Matematyka nazywana jest królową nauk. Gdy myślimy o matematykach, przychodzą nam do głowy nobliwi profesorowie z siwymi brodami, bądź romantyczni narwańcy w stylu Piotra Fermata, który będąc na spacerze wpadł na pomysł dowodu matematycznego. Zaczął więc zapisywać ów dowód na pierwszej płaskiej powierzchni, jaką znalazł, która to przestrzeń okazała się być… dorożką, która w środku spisywania po prostu mu odjechała.
Co innego statystyka. Statystyka nie jest uważana za naukę, raczej wpycha się ją w szufladkę „wyrafinowane kłamstwa”. Wystarczy przejrzeć cytaty dotyczące statystyki:
• Jeśli mój sąsiad codziennie bije swoją żonę, ja zaś nie biję jej nigdy, to w świetle statystyki obaj bijemy je co drugi dzień – George Bernard Shaw;
• Istnieją trzy rodzaje kłamstw: kłamstwa, okropne kłamstwa oraz statystyki – Benjamin Disraeli;
• Jedna śmierć to tragedia, milion – to statystyka – Erich Maria Remarque.
Skąd ta zła prasa statystyki? Przecież z matematyką dzieli wspólny pień, którym jest rachunek prawdopodobieństwa. Hipotez jest kilka. Jedną z nich jest ta, która mówi, że to przez samych statystyków, którzy tak manipulują danymi, by udowodnić swoje tezy. Druga hipoteza mówi o tym, że powód kryje się w samym rachunku prawdopodobieństwa i jego odbiorze przez ludzki umysł. Trzecia hipoteza wreszcie dotyczy tego, że statystyka towarzyszy nam w codziennym życiu, lecz po prostu jej nie rozumiemy. Zajmę się wszystkimi trzema hipotezami.
To przez statystyków
Drodzy Państwo. Spodziewam się, że gdy skończycie ten kurs, będziecie potrafili udowodnić dowolną prawdę z dowolnych danych – zasłyszane na kursie statystyki.
Statystyka to potężne narzędzie, na które składa się bardzo wiele rozmaitych technik. Co więcej, na podstawie już obecnych technik wciąż powstają nowe. Pomaga w tym rozwój komputerów, które potrafią wykonać zadane obliczenia coraz szybciej i sprawniej. Wystarczy zdać sobie sprawę z tego, że dowolny dzisiejszy smartfon jest potężniejszym komputerem niż dowolny dostępny dla przeciętnego konsumenta komputer z początku wieku. To ogromny postęp. Dzięki komputerom statystycy mogą więcej.
Więcej oczywiście nie znaczy lepiej. Duża część statystyków pracuje dla agencji badawczych, gdzie na podstawie prób badawczych wysnuwane są wnioski na temat produktów, kondycji partii politycznych czy opinii Polaków. Potem jednak nawet najbardziej rzetelny statystyk wypuszcza swoją pracę z rąk i klient przedstawia te dane tak, jak mu wygodnie. Czy jest to manipulacja? Owszem, niekoniecznie jednak statystyczna. Tego typu manipulacje dość łatwo jest jednak wykryć, wystarczy przyjrzeć się prezentowanym danym stosując kilka prostych kryteriów:
***
Kilka prostych kryteriów
- Czy podana jest próba badawcza? W przypadku ogólnopolskich badań przyjmuje się, że próba N=1000 jest wystarczająca do wnioskowania statystycznego. Na szczęście coraz częściej publikuje się nie tylko informację o liczebności próby, ale również o maksymalnym błędzie pomiaru.
- Czy na wykresach są pokazane wartości? Ogólnikowe hasło oraz wykres bez skali i procentów? Zdarza się to niestety dość często. Bez skali porównawczej ludzkie oko nie jest w stanie wychwycić różnic między słupkami, dzięki czemu można optycznie wywołać wrażenie przewagi jednych danych nad innymi.
- Czy jest przytoczone pytanie? Pokazywane wykresy powstały na podstawie jakiś pytań, zadawanych respondentom. Nie jest bez znaczenia, czy pytano o „ulubionego polityka” czy „najmniej znienawidzonego polityka”, a zarówno jedno, jak i drugie może kryć się pod nagłówkiem „sympatia do polityków”.
***
Oczywiście, czasami istnieje pokusa, by z dowolnych danych wysnuć dowolną „prawdę”, problemem jest tylko to, że statystycy nie pretendują do miana wróżek: naszym zadaniem w większości przypadków nie jest zbadanie prawdy jako takiej, tylko pokazanie, że rzeczywistość można spróbować opisać w pewnych kategoriach. Dobrym przykładem są badania segmentacyjne (które, nawiasem mówiąc, leżą u podstaw każdego psychotestu). W badaniu segmentacyjnym staramy się zaklasyfikować daną osobę, na podstawie jej odpowiedzi na pytania, do poszczególnych typów. Oczywiście, zdajemy sobie sprawę z tego, że typy te są zbiorem pewnych idealnych cech. Dlatego też po wykonaniu psychotestu trochę kręcimy nosem, gdy nie wszystko się zgadza, ale jesteśmy pod wrażeniem, gdy zgadza się „coś”. W badaniu segmentacyjnym człowiek trafia do określonej przegródki z określonym, większym niż w przypadku pozostałych przegródek, prawdopodobieństwem. W praktyce oznacza to, że uzyskawszy „typ B” z sześciu możliwych typów najlepiej tu właśnie pasujemy – bądź też, jeśli kto woli – do innych typów pasujemy jeszcze mniej. Statystycy się z tym godzą. Nasza dziedzina bazuje na rachunku prawdopodobieństwa, mamy więc określoną szansę trafić z naszym przewidywaniem. Na czym polega to przewidywanie? Na słoniu, który połknął Gaussa.
Słoń, który połknął Gaussa
Pamiętacie moment, gdy w „Małym Księciu” Pilot skarży się, że nikt nie jest przerażony jego rysunkiem, który przypomina kapelusz? Tymczasem: mój obrazek nie przedstawiał kapelusza. To był wąż boa, który trawił słonia1.

Wspominam o tym, gdyż podstawą większości (lecz nie wszystkich) statystycznych przewidywań jest krzywa rozkładu normalnego, zwana również krzywą Gaussa. Osobliwie, wygląda ona dość podobnie do kapelusza, bardziej może przypominając sombrero niż włoską fedorę:
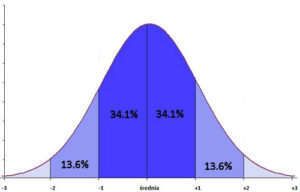
Krzywa rozkładu normalnego opisuje rozkład dowolnej ciągłej cechy w dostatecznie licznej populacji. Weźmy pod uwagę wzrost i spróbujmy przełożyć poprzednie zdanie ze statystycznego na ludzki. Na podstawie rozkładu normalnego spodziewamy się, że najwięcej będziemy mieć osób o średnim wzroście (środek wykresu), następnie będzie całkiem dużo osób, których wzrost będzie nieznacznie odbiegał od średniego (najciemniejszy niebieski kolor pokazuje, że spodziewamy się 34.1% osób nieznacznie wyższych i kolejnych 34.1% nieznacznie niższych), zaś wysokich i naprawdę wysokich oraz niskich i naprawdę niskich będziemy mieć w naszej populacji niewielu (kolejne odcienie niebieskiego). Brzmi rozsądnie, ale to dopiero początek: aby uzyskać tak piękny wykres, potrzebujemy zbadania dostatecznie dużej populacji; niestety, zazwyczaj brakuje na to środków. Musimy więc wylosować próbę z owej populacji i liczyć na to, że nasza próba będzie dobrze oddawać cechy obecne w populacji2. To jest moment, w którym wkracza rachunek prawdopodobieństwa – od doboru próby, tego, czy jest ona w pełni losowa czy też dobrana celowo (patrz ramka nr 2) oraz od jej liczebności będzie zależeć jakość wnioskowania statystycznego.
Do przeprowadzenia uprawnionego wnioskowania statystycznego potrzebujemy więc przynajmniej: dobrze dobranej próby oraz założenia o spełnieniu warunku normalności rozkładu. To wszystko? Oczywiście nie.
***
Rodzaje prób
Próba losowa: to taka próba, w przypadku której każdy element populacji ma dokładnie taką samą szansę znalezienia się w próbie. Jeśli wybieramy próbę spacerując ulicą, nie spełniamy pełnej losowości, gdyż omijamy w ten sposób osoby, które zostały w domu. Jeśli jednak ustawimy ankieterów przed lokalami wyborczymi i poprosimy ich, by co dziesiątą osobę pytali o oddany głos – próba powinna być w pełni losowa, gdyż każdy wychodzący z lokalu wyborczego może być akurat dziesiątym z kolei. Tak dobrana próba powinna umożliwić wnioskowanie statystyczne.
Próba celowa: to próba, która dobierana jest z populacji „pod warunkiem”. Próbą celową będzie na przykład dobór polityków do studia telewizyjnego, komentujących wyniki wyborów. Zapraszając pięć osób zazwyczaj nie losuje się dowolnych polityków (gdyż istnieje niezerowa szansa, że wylosuje się np. polityków z tej samej partii), lecz dobiera się ich w taki sposób, by różnili się poglądami. W większości przypadków, gdy mamy do czynienia z próbą celową, nie możemy przeprowadzić wnioskowania statystycznego.
***
Jestem statystykiem, potrafię liczyć. Ale dopiero od tysiąca w górę.
Dlaczego większość ogólnopolskich sondaży przeprowadza się na próbie 1000 osób3? Wróćmy na chwilę do rozkładu normalnego: jak można policzyć, zsumowany kolor ciemnoniebieski i niebieski da około 95%. Statystycy zwykli mówić, że na tej podstawie oczekują, iż 95% osób w populacji będzie miało daną cechę (np. wzrost) mniej więcej średnią +/- dwa odchylenia standardowe. Upraszczając nieco sprawę4 można powiedzieć, że odchylenie standardowe to „średnie odchylenie od średniej”, czyli wartość, o jaką dowolnie wylosowany przedstawiciel populacji powinien różnić się od wartości średniej. Wracając do przykładu ze wzrostem: jeśli średni wzrost wynosi 170 centymetrów, zaś odchylenie standardowe wynosi 10 centymetrów, to 64.2% naszej populacji powinno mieć wzrost 160-180 centymetry (jedno odchylenie standardowe od średniej), zaś około 95% populacji – 150-190 centymetrów (dwa odchylenia standardowe od średniej).
Kończąc dygresję: dobierając próbę musimy dążyć do tego, by odzwierciedlała ona populację. Próba 1000 osób generuje błąd pomiaru na poziomie 3.1%, co powszechnie uznaje się za „dopuszczalny błąd”. W praktyce oznacza to, że wszelkie wartości, które są nam prezentowane na wykresach i w tabelach mogą różnić się o około 3.1% w każdą stronę. Dla porównania: próba o liczebności (N=) 400 będzie obarczona 4.9% błędem, N=200 – 6.9% błędem, zaś pytając 80 Polaków o opinię, nasze wyniki obarczone będą 11% błędem oszacowania (co oznacza, że jeżeli wśród owych 80 Polaków znajdzie się 40% takich, którzy np. lubią jabłka, to wśród wszystkich Polaków odsetek osób lubiących jabłka będzie między 29% a 51%. To zdecydowanie za duży rozrzut, jak na wnioskowanie statystyczne).
Szansa jedna na milion
Magowie obliczyli, że szanse jedna na milion sprawdzają się w dziewięciu przypadkach na dziesięć.
Powyższy cytat z „Równoumagicznienia” Terry’ego Pratchetta jest oczywiście absurdalny, jednak dobrze oddaje naturę ludzkiego umysłu. Zestawienie statystyk, bazujących na rachunku prawdopodobieństwa z nieprawdopodobnymi przypadkami, którymi usiane jest ludzkie życie, siłą rzeczy musi wypaść na niekorzyść statystyki. Jest ona z tego punktu widzenia zwyczajnie nudna. Osobliwości opisywane przez Nagrodę Darwina, ponadprzeciętne umiejętności sportowców czy przypadki jedne na milion są dużo bardziej pociągające – nasz umysł ciąży ku tym skrajnościom, które – ze statystycznego punktu widzenia – są gdzieś daleko na krańcach krzywej Gaussa. To właśnie dzięki temu, że życie płata figle, o którym nie śniło się statystykom, nauka, którą się zajmujemy, jest mało zabawna. Ma jednak jeden zasadniczy plus. Zwykle pokazuje jak jest.
Z dokładnością do 95%.
——
1 Antoine de Saint-Exupéry, „Mały Książę”, s.8, Muza S.A., Warszawa 2002
2 Jeśli wrócimy do rysunku węża, który połknął słonia, możemy stwierdzić, że ze statystycznego punktu widzenia, jako wykres jest nieco lewoskośny. Jeśli przedstawiałby wzrost w danej populacji, należałby się przyjrzeć, czy przypadkiem do próby nie zaplątał się oddział przedszkolaków, zaniżających średnią wzrostu.
3 Nawiasem mówiąc ostatnio coraz więcej ogólnopolskich sondaży przeprowadza się na próbie 960 osób. Dlaczego? Dzięki zaokrągleniom błąd pomiaru dla próby 1000 i 960 wynosi „tyle samo”, czyli 3.1%. „Tyle samo” nie oznacza tyle samo – ograniczenie wielkości próby możliwe jest dzięki zaokrągleniu wielkości błędu do jednego miejsca po przecinku.
4 Gdyż nie chcemy tu żadnych matematycznych wzorów. Według Rogera Penrose’a każdy matematyczny wzór w artykule lub książce redukuje liczbę czytelników o połowę. Aż strach pomyśleć jakim powodzeniem cieszyłby się jego „Nowy umysł cesarza”, gdyby nie owe kilkaset wzorów, które tam zawarł.
Łukasz Widła-Domaradzki